发布时间: 2025-09-23
作者:胡丹 专利代理师
引言
在生物医药领域,涉及氨基酸序列和/或核苷酸序列的发明专利申请,一般都需要制作序列表,这是本领域专利代理师所熟知的。然而随着技术的不断发展,特别是小核酸以及核酸修饰技术的发展,单纯显示碱基序列信息的序列表不再能满足全面表征核酸信息的要求。
自2022年7月1日起,无论是国际申请、还是各国家或地区的申请,所提交的序列表都必须符合世界知识产权组织的标准ST.26。与此前的ST.25相比,ST.26下的序列表作为单一序列表,可确保各知识产权局在应用序列规则时保持一致,确保数据与国际核苷酸序列数据库合作联盟INSDC(由DDBJ、EMBL-EBI的ENA、NCBI的GenBank组成的联盟)数据库提供方的要求兼容,此外,序列注解(特征键和限定符)被纳入可公开检索的数据库中。
一般对于常规的核苷酸/氨基酸序列,使用WIPO Sequence桌面工具填入申请相关的法律信息和序列信息,导出XML格式的序列表即可。然而对于包含了各种修饰的核苷酸序列而言,既往制作序列表的经验是不够的,有待在序列表制作工具中不断应用和尝试。
案情介绍
笔者近日在实务工作中,遇到了一种比较复杂的修饰DNA序列(以下简称“修饰序列”),其带有4种不同类型的中间核苷酸碱基修饰和末端核苷酸修饰,于是仔细研读了WIPO发布的文件(详见参考文献),了解到WIPO Sequence桌面工具的序列注解功能。本文中,笔者将以具体的“修饰序列”为例,分析此类序列表的制作过程,以期为同业人员提供参考。
修饰序列:ACGCTCACGCTCGCTGCTACGTTGACCGCGGGGTC/Spacer18/TCATCGCAGTGTCGCCGTGGGCGACC/idSp/GCTGCCCA-Spacer C3,其中,
(1)“CGGGGTC” 和“GCCCA” 为2’甲氧基修饰碱基;
(2)Spacer 18可添加在核苷酸序列的5’端或3’端,作为非核酸的柔性linker替代一段核酸序列,提高寡核酸各部分间的灵活性;同时spacer 18不会与体系中其他核酸链产生互补配对,可用于隔开不同的基因以减少不利的位阻或相互作用,常用于辅助核酸链形成发夹结构;
(3)idSp是指不带有碱基的空脱氧核苷酸,因为该位置不含碱基,无法形成氢键,又被称作AP site(abasic site);
(4)Spacer C3可添加在核苷酸序列的5’端或3’端,常用于“替代”一段序列中未知的碱基,放在寡核苷酸的3’端,封阻寡核苷酸的延伸,其对核酸外切酶有一定抗性,也可引入到固相载体与寡核苷酸之间,减少两者间的空间位阻。
Spacer18处于序列中间位置,由于Spacer18不属于任何碱基类型,Spacer18两端的每一部分都是一个单独的核苷酸序列,且均多于10个碱基,需要分别制作序列表并编号,其中:
Spacer18左侧的序列为:
ACGCTCACGCTCGCTGCTACGTTGACCGCGGGGTC,序列编号为SEQ ID NO.1;
Spacer18右侧的序列为:
TCATCGCAGTGTCGCCGTGGGCGACC/idSp/GCTGCCCA -Spacer C3,序列编号为SEQ ID NO.2;
前述(1)-(4)中已经列出了修饰序列(已拆解为SEQ ID NO.1和SEQ ID NO.2)中包含的4种修饰,接下来需要去“STANDARD ST.26”中查找相应修饰在制作ST.26下的序列表时各自对应的序列注解(包括特征建和限定符)。
处理方式
1.注释SEQ ID NO.1
SEQ ID NO.1长度为35nt,在第29-35位有7个2’甲氧基修饰碱基,对照“Table 2:List of modified nucleotides ”分别找到2’甲氧基修饰C简写“cm”, 2’甲氧基修饰G简写“gm”, 2’甲氧基修饰T简写“tm”。
按照常规程序,在WIPO Sequence桌面工具中输入SEQ ID NO.1的核苷酸序列,然后,进行序列注解:
(1)注解第29位为修饰碱基C,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中选29,在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选择“cm”;
(2)注解第30-33位修饰碱基G,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中选30..33,在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选择“gm”;
(3)注解第34位修饰碱基T、第35位修饰碱基C参考以上描述,在此不赘述;
(4)注解SEQ ID NO.1的第35位碱基C,其连接至Spacer18,在“特征”下点击“添加功能”,在“特征键”中选择“misc_feature”,在右侧“特征位置”中选35,在“限定符”下面选择“限定符名称”为“note”,右侧的“限定符值”输入“joined to another nucleic acid via Spacer 18”或“attached to Spacer 18,which is joined to another nucleic acid”。
2.注释SEQ ID NO.2
SEQ ID NO.2长度为35nt,在第27位有1个idSp,第31-35位有5个2’甲氧基修饰碱基,对照“Table 2:List of modified nucleotides ”,2’甲氧基修饰A没有简写,选择mod_base = OTHER,note = 2' O Methyl adenosine来注解。
按照常规程序,在WIPO Sequence桌面工具中输入SEQ ID NO.2的核苷酸序列,然后,进行序列注解:
(1)注解第1位碱基T,其连接至Spacer18,在“特征”下点击“添加功能”,在“特征键”中选择“misc_feature”,在右侧“特征位置”中选1,在“限定符”下面选择“限定符名称”为“note”,右侧的“限定符值”输入“joined to another nucleic acid via spacer 18” 或“attached to Spacer 18,which is joined to another nucleic acid”;
(2)注解第27位“idSp”,“idSp”在核苷酸序列中表示为“n”,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中选27,在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选择“OTHER”,添加“限定符名称”为“note”,右侧的“限定符值”输入“abasic site”;
(3)注解第31位为修饰碱基G,第32-34位修饰碱基C参考以上描述,在此不赘述;
(4)注解第35位修饰碱基A,在“特征”下点击“添加功能”,在“特征键”中选择“modified_base”,在右侧“特征位置”中选35,在“限定符”下面选择“限定符名称”为“mod_base”,右侧的“限定符值”选择“OTHER”,添加“限定符名称”为“note”,右侧的“限定符值”输入“2' O Methyladenosine”;
(5)注解第35位碱基A,其连接至Spacer C3,在“特征”下点击“添加功能”,在“特征键”中选择“misc_feature”,在右侧“特征位置”中选35,在“限定符”下面选择“限定符名称”为“note”,右侧的“限定符值”输入“attached to Spacer C3”。
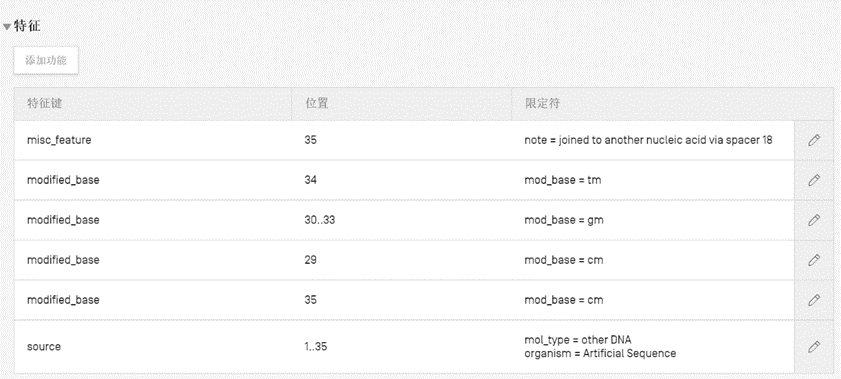
图1 WIPO Sequence桌面工具中SEQ ID NO.1特征部分的注释结果
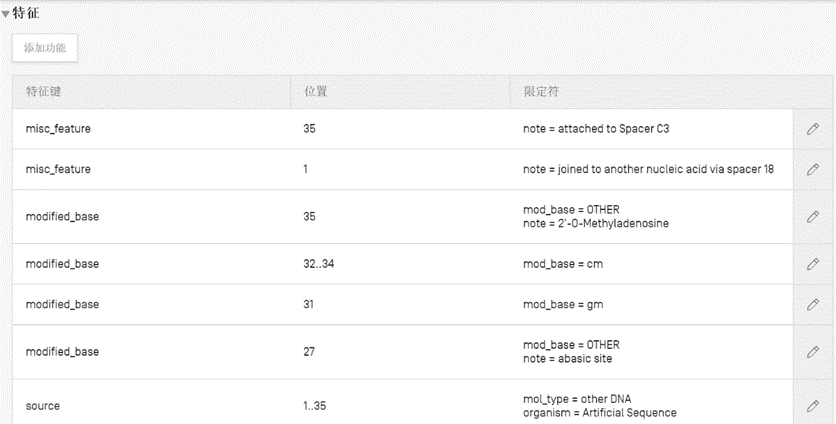
图2 WIPO Sequence桌面工具中SEQ ID NO.2特征部分的注释结果
对于包含修饰的复杂生物序列,在ST.26下制作序列表时,需要分析序列的结构组成,修饰类型和位置,然后在WIPO Sequence桌面工具中进行相应的注解。ST.26中的内容非常丰富,注解功能十分强大,涵盖了专利代理师日常遇到的各种非常规序列类型,例如核苷酸修饰、核酸类似物、支链核苷酸序列,支链氨基酸序列、环肽等,并且给出了具体的定义和实例,便于代理师制作序列表时对照查阅,并在WIPO Sequence桌面工具中不断应用和尝试,以积累更多的经验,更好地服务于生物医药领域案件的撰写。
以上是笔者关于ST.26下复杂核苷酸序列表制作的一点经验分享,供同行在处理类似问题时参考。
参考文献
1. 产权组织标准ST.26简介。
2. WIPO Sequence桌面工具。
3. STANDARD ST.26。